从 v1.0.0 升级到 v1.0.1
本文介绍如何将 Harvester v1.0.0 升级到 v1.0.1。
我们仍在努力实现零停机升级。请在升级 Harvester 集群之前按照以下步骤操作:
警告
- 在升级 Harvester 集群之前,我们强烈建议:
- 关闭所有虚拟机(Harvester GUI -> Virtual Machines -> 选择虚拟机 -> Actions -> Stop)。
- 备份虚拟机。
- 不要在升级期间操作集群,例如,创建新的虚拟机、上传新的镜像等。
- 确保你的硬件符合首选硬件要求。这是因为升级会消耗中间资源。
- 确保每个节点至少有 25 GB 的可用空间 (
df -h /usr/local/)。
警告
确保所有节点的时间同步。建议使用 NTP 服务器来同步时间。如果你在安装期间没有配置 NTP 服务器,你可以在每个节点上手动添加一个 NTP 服务器:
$ sudo -i
# 添加时间服务器
$ vim /etc/systemd/timesyncd.conf
[ntp]
NTP=0.pool.ntp.org
# 启用并启动 systemd-timesyncd
$ timedatectl set-ntp true
# 检查状态
$ timedatectl status
警告
- 连接到 PCI 网桥的 NIC 可能会在升级后重命名。请查看知识库了解更多信息。
创建版本
登录到你的其中一个服务器节点。
成为 root 并创建一个版本:
rancher@node1:~> sudo -i
node1:~ # kubectl create -f https://releases.rancher.com/harvester/v1.0.1/version.yaml
version.harvesterhci.io/1.0.1 created
备注
默认情况下,ISO 镜像是从 Harvester release 服务器下载的。为了让升级更快更顺畅,你也可以先将 ISO 文件下载到本地 HTTP 服务器,然后替换 version.yaml manifest 中的 isoURL 值。
例如:
# 先从 release server 下载 ISO,假设它存储在 http://10.10.0.1/harvester.iso
$ sudo -i
$ curl -fL https://releases.rancher.com/harvester/v1.0.1/version.yaml -o version.yaml
$ vim version.yaml
apiVersion: harvesterhci.io/v1beta1
kind: Version
metadata:
name: v1.0.1
namespace: harvester-system
spec:
isoChecksum: <SHA-512 checksum of the ISO>
isoURL: http://10.10.0.1/harvester.iso
releaseDate: '20220408'
开始升级
请务必先阅读本文档顶部的警告内容。
导航到 Harvester GUI,然后单击仪表板页面上的升级按钮:
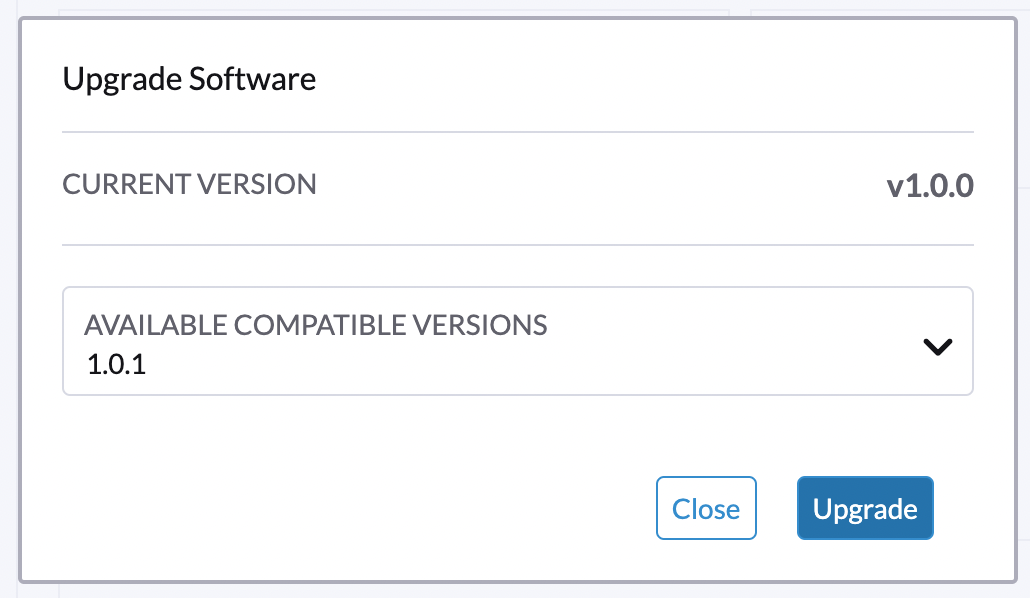
选择要升级的版本:
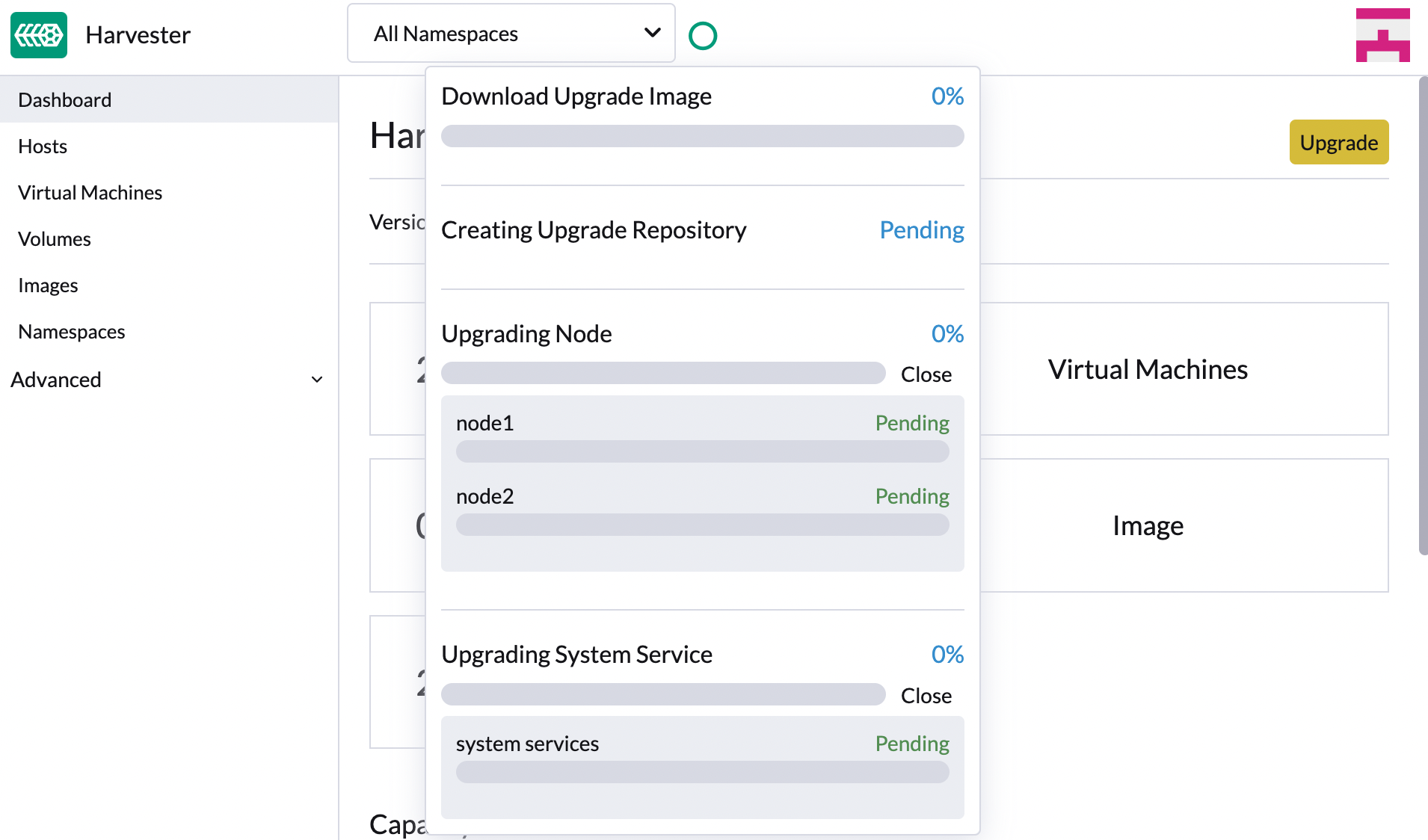
单击顶部的圆圈以显示升级进度:
已知问题
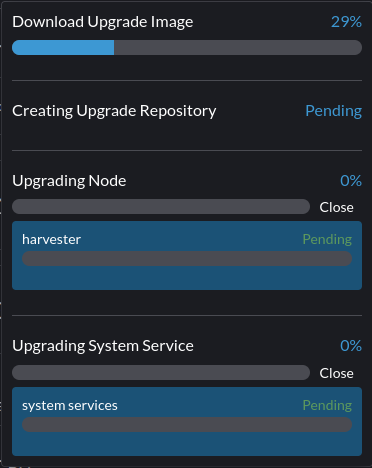
下载升级镜像失败
说明
无法完成升级镜像的下载:
解决方法
删除当前的升级并重新开始。
# 登录到其中一个 server 节点
$ sudo -i
# 列出当前的升级,不同 deployment 的名称会不同
$ kubectl get upgrades.harvesterhci.io -n harvester-system
NAMESPACE NAME AGE
harvester-system hvst-upgrade-77cks 119m
$ kubectl delete upgrades.harvesterhci.io hvst-upgrade-77cks -n harvester-system我们建议将 ISO 文件镜像到本地 webserver,请查看上一节中的说明。
卡在升级系统服务
说明
升级卡在升级系统服务中。
在 Rancher pod 中可以找到类似以下的日志:
[ERROR] available chart version (100.0.2+up0.3.8) for fleet is less than the min version (100.0.3+up0.3.9-rc1)
[ERROR] Failed to find system chart fleet will try again in 5 seconds: no chart name found
解决方法
删除 Rancher 集群仓库并重新启动 Rancher Pod:
# 登录到一个 server 节点,并先成为 root
kubectl delete clusterrepos.catalog.cattle.io rancher-charts
kubectl delete clusterrepos.catalog.cattle.io rancher-rke2-charts
kubectl delete clusterrepos.catalog.cattle.io rancher-partner-charts
kubectl delete settings.management.cattle.io chart-default-branch
kubectl rollout restart deployment rancher -n cattle-system相关问题
虚拟机迁移失败
说明
- 节点一直在
Pre-draining状态。 - 该节点上有虚拟机(检查
virt-launcher-xxxpod),这些虚拟机无法热迁移出节点。
- 节点一直在
解决方法
关闭虚拟机,你可以通过以下方式执行此操作:
- 使用 GUI。
- 使用
virtctl命令。
相关问题
fleet-local/local: another operation (install/upgrade/rollback) is in progress
说明
你在输出中看到 bundle 具有
fleet-local/local: another operation (install/upgrade/rollback) is in progress状态:kubectl get bundles -A相关问题